
티스토리 뷰
메모리 관리의 개요
메모리 주소
- 1 바이트로 나뉜 메모리의 각 영역은 메모리 주소로 구분하는데 보통 0번지부터 시작
- cpu메모리에 있는 내용을 가져오거나 작업 결과를 작업 결과를 메모리에 저장하기 위하 메모리 주소 레지스터(MBR) 사용
메모리 관리의 복잡성
메모리 관리의 복잡성
- 메모리는 폰노이만 구조의 컴퓨터에서 하나의 프로그램만 실행시킴으로 메모리 관리가 단순함
- 시분할 시스템에서는 운영체제를 포함한 모든 응용 프로그램이 메모리에 올라와 실행되기 때문에 메모리 관리가 복잡함
메모리 관리의 이중성
메모리 관리의 이중성
- 프로세스 입장에서는 메모리를 독차지 하려 하고, 메모리 관리자 입장에서는 관리를 효율적으로 하고 싶어함
소스코드의 번역과실행
언어 번역 프로그램의 종류
- 컴파일러 : 소스코드를 컴퓨터가 실행할 수 있는 기계어로 번역한 후 한꺼번에 실행(C, JAVA etc..)
- 인터프리터 : 소스코드를 한 행씩 번역하여 실행(JS etc..) //에러찾기가 어렵고 최적화 하기 힘듬
컴파일러의 목적
- 오류발견 : 소스코드에서 오류를 발견하여 실행 시 문제가 없도록 하는것
- 코드 최적화 : 소스코드를 간결하게 정리하여 자바와 인터프리터를 사용하는 자바스크립트 비교
컴파일러와 인터프리터의 차이
- 컴파일러를 사용하는 자바와 인터프리터를 사용하는 자바스크립트 비교
자바
- 변수 선언해야함
- 컴파일 후 실행
- 오류찾기와 코드 최적화, 분할 컴파일에 의한 공동 작업이 가능한 장점을 가짐
- 대형 프로그램에 사용
자바스크립트
- 변수를 선언할 필요가 없음
- 한 줄씩 실행
- 실행이 편리하다는 장점을 가짐
- 간단한 프로그램에 사용
컴파일 과정
1. 소스코드 작성 및 컴파일
2. 목적코드와 라이브러리 연결
3. 동적 라이브러리를 포함하여 최종 실행
메모리 관리자의 역할
메모리 관리자
- 메모리 관리를 담당하는 하드웨어
메모리 관리자의 작업
- 가져오기 작업 : 프로세스와 데이터를 메모리로 가져옴
- 배치 작업 : 가져온 프로세스와 데이터를 메모리의 어떤 부분에 올려놓을지 결정
- 재배치 작업 : 꽉 차있는 메모리에 새로운 프로세스를 가져오기 위해 오래된 프로세스를 내보냄
메모리 관리자의 정책
- 가져오기 정책 : 프로세스가 필요로 하는 데이터를 언제 메모리로 가져올지 결정하는 정책
- 배치 정책 : 가져온 프로세스를 메모리의 어떤 위치에 올려놓을지 결정하는 정책
- 재배치 정책 : 메모리가 꽉찼을때 메모리 내에 있는 어떤 프로세스를 내보낼지 결정하는 정책
메모리 주소
32bit CPU와 64bit CPU의 차이
CPU의 비트
- 한 번에 다룰 수 있는 데이터의최대 크기를 워드(word)라고 부름
- 32bit cpu는 한 번에 다룰 수 있는 데이터의 최대 크기가 32bit(= 1 word)
- 32bit cpu 내의 레지스터 크기는 전부 32bit, 산술 논리 연산장치와 대역폭도 32bit
32bit CPU의 메모리 크기
- 표현할 수 있는 메모리주소의 범위가 0~2^32 -1, 총 개수가 2^32
- 16진수로 나타내면 00000000 ~ FFFFFFFF, 총 크기는 2^32 바이트 (약 4GB)
64bit CPU의 메모리 크기
- 0 ~ 2^64-1 번지의 주소 공간을 제공
- 총 크기가 2^64바이트, 약 16,777,216TB로 거의 무한대에 가까운 메모리 사용 가능
물리 주소 공간과 논리주소 공간
- 물리 주소 공간 : 하드웨어 입장에서 바라본 주소 공간으로 컴퓨터마다 크기가 다름
- 논리 주소 공간 : 사용자 입장에서 바라본 주소 공간
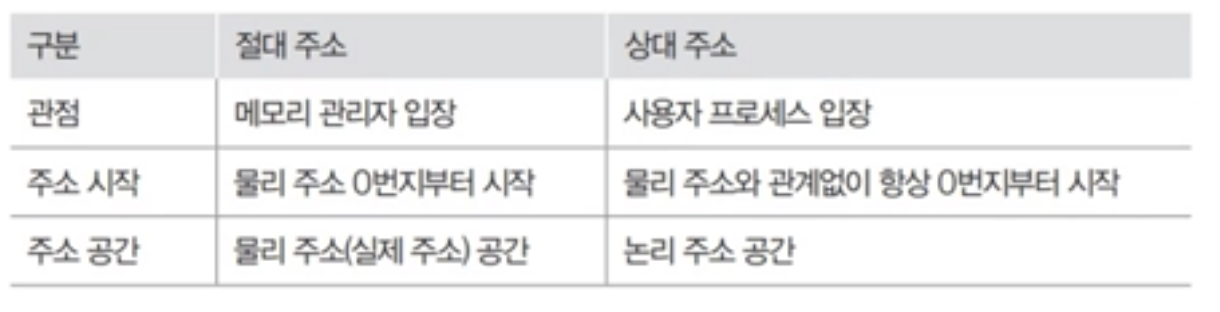
절대주소와 상대주소
단순메모리 구조
- 한 번에 한 가지 일만 처리하는 일괄처리 시스템에서 볼 수 있음
- 메모리를 운영체제 영역과 사용자 영역으로 나누어 관리
단순메모리 구조에서 사용자 프로세스 적재
- 사용자 프로세스는 운영체제 영역을 피하여 메모리에 적재
- 사용자 프로세스가 운영체제의 크기에 따라 매번 적재되는 주소가 달라지는 것은 번거로움. 이를 개선하여 사용자 프로세스를 메모리의 최상위부터 사용
-> 그러나 메모리를 거꾸로 사용하기 위해 주소를 변경하는 일이 복잡하기 때문에 잘 쓰이지 않음
경계레지스터
- 운영체제 영역과 사용자 영역 경계 지점의 주소를 가진 레지스터
- CPU 내에 있는 경계 레지스터가 사용자 영역에 운영체제 영역으로 침범하는 것을 막아줌
- 메모리 관리자는 사용자가 작업을 요청할 때마다 경계 레지스터의 값을 벗어나는지 검사하고, 만약 경계레지스터를 벗어나는 작업을 요청하는 프로세스가 있으면 그 프로세스를 종료
절대주소
- 실제 물리주소를 가리키는 주소
- 메모리 주소 레지스터가 사용하는 주소
- 컴퓨터에 꽂힌 램 메모리의 실제주소
상대주소
- 사용자 영역이 시작되는 번지를 0번지로 변경하여 사용하는 주소
- 사용자 프로세스 입장에서 바라본 주소
- 절대주소와 관계없이 항상 0번지 부터 시작
- 프로세스 입장에서 상대 주소가 사용할 수 없는 영역의 위치를 알 필요가 없고, 주소가 항상 0번지 부터 시작하기 때문에 편리
절대주소와 상대주소의 차이
- 논리 주소 공간은 상대주소를 사용하는 주소 공간
- 물리 주소 공간은 절대주소를 사용하는 주소 공간
메모리 오버레이
메모리 오버레이
- 프로그램의 크기가 실제 메모리(물리 메모리)보다 클 때 전체 프로그램을 메모리에 가져오는 대신 적당한 크기로 잘라서 가져오는 기법
- 메모리 오버레이를 사용하면 물리 메모리보다 더 큰 프로그램도 실행이 가능하다.
메모리 오버레이의 작동방식
- 프로그램이 실행되면 필요한 모듈만 메모리에 올라와 실행
메모리 오버레이의 의미
- 한정된 메모리에서 메모리보다 큰 프로그램의 실행 가능
- 프로그램 전체가 아니라 일부만 메모리에 올라와도 실행 가능
스왑영역
- 메모리가 모자라서 쫒겨난 프로세스를 저장장치의 특별한 공간에 모아두는 영역
- 메모리에서 쫒겨났다가 다시 돌아가는 데이터가 머무는 곳이기 때문에 저장장치는 장소만 빌려주고 메모리 관리자가 관리
- 사용자는 실제 메모리의 크기와 스왑영역의 크기를 합쳐서 전체 메모리로 인식하고 사용
스왑인과 스왑아웃
- 스왑인 : 스왑 영역에서 메모리로 데이터를 가져오는 작업
- 스왑아웃 : 메모리에서 스왑 영역으로 데이터를 내보내는 작업
다중 프로그래밍 환경에서의 메모리 할당
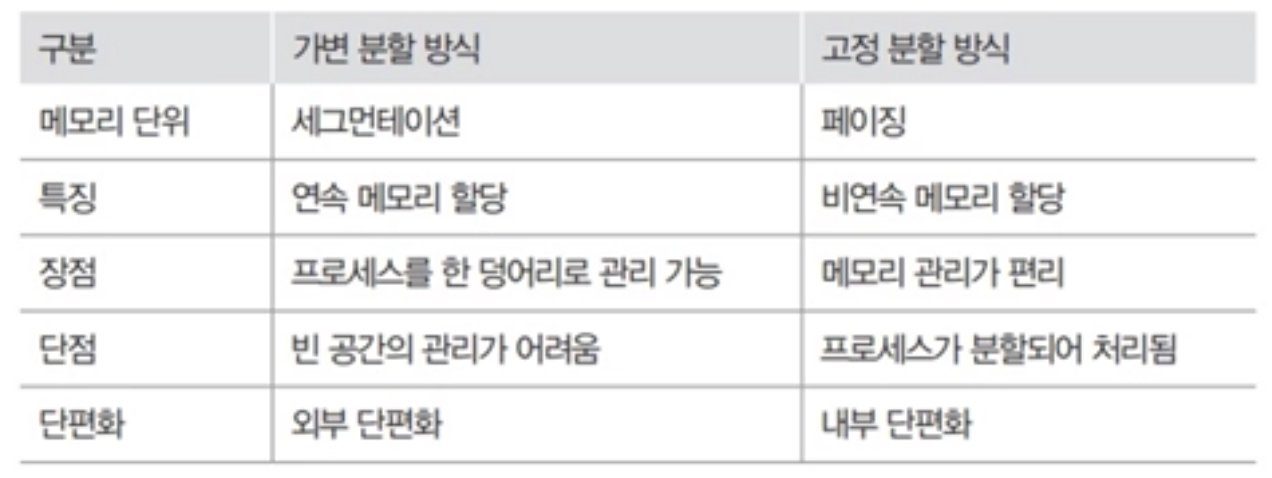
메모리 분할 방식
메모리에 여러 개의 프로세스를 배치하는 방법
- 가변 분할 방식 : 프로세스의 크기에 따라 메모리를 나누는것
- 고정 분할 방식 : 프로세스의 크기에 상관없이 메모리를 같은 크기로 나누는 것
메모리 분할 방식의 구현
- 가변 분할 방식
- 프로세스의 크기에 맞게 메모리가 분할
- 메모리의 영역이 각각 다름
- 연속 메모리 할당
- 고정 분할 방식
- 프로세스의 크기에 상관없이 메모리가 같은 크기로 나뉨
- 큰 프로세스가 메모리에 올라오면 여러 조각으로 나누어 배치
- 비연속 메모리 할당
가변 분할 방식의 장단점
- 장점 : 프로세스를 한 덩어리로 처리하여 하나의 프로세스를 연속된 공간에 배치
- 단점 : 비어 있는 공간을 하나로 합쳐야 하며, 이 과정에서 다른 프로세스의 자리도 옮겨야 하므로 메모리 관리가 복잡함
고정 분할 방식의 장단점
- 장점 : 메모리를 일정한 크기로 나누어 관리하기 때문에 메모리 관리가 수월(가변 분할 방식의 메모리 통합 같은 부가적인 작업을 할 필요가 없음)
- 단점 : 쓸모없는 공간으로 인해 메모리 낭비가 발생할 수 있음
가변 분할 방식의 메모리 관리
가변 분할 방식과 외부 단편화
- 프로세스 A,B,C,D,E를 순서대로 배치했을 때 프로세스 B와 D가 종료되면 18KB와 17KB의 빈 공간이 생김
- 이후 18KB보다 큰 프로세스가 들어오면 적당한 공간이 없어 메모리를 배정하지 못하는데, 가변 분할 방식에서 발생하는 이러한 작은 빈 공간을 외부 단편화라고 함
외부 단편화 해결
- 메모리 배치 방식 : 작은 조각이 발생하지 않도록 프로세스를 배치하는것
- 조각모음 : 조각이 발생했을 때 작은 조각들을 모아서 하나의 큰 덩어리로 만드는 작업
메모리 배치 방식
- 최초배치
-> 프로세스를 메모리의 빈 공간에 배치할 때 메모리에서 적재 가능한 공간을 순서대로 찾다가 첫 번째로 발견한 공간에 프로세스를 배치하는 방법
- 최적배치
-> 메모리의 빈 공간을 모두 확인한 후 적당한 크기 가운데 가장 작은 공간에 프로세스를 배치하는 방법
- 최악배치
-> 빈 공간을 모두 확인한 후 가장 큰 공간에 프로세스를 배치하는 방법
메모리 배치 방식 비교
- 최초배치
-> 빈 공간을 찾아다닐필요가 없음
- 최적배치
-> 빈 공간을 모두 확인하는 부가적인 작업이 있지만 딱 맞는 공간을 찾을 경우 단편화가 일어나지 않음
-> 딱 맞는 공간이 없을때는 아주 작은 조각을 만들어내는 단점이 있음
- 최악배치
-> 프로세스를 배치하고 남은 공간이 크기 때문에 쓸모가 있음
-> 빈 공간의 크기가 클 때는 효과적이지만 빈 공간의 크기가 점점 줄어들면 최적배치 처럼 작은 조각을 만들어냄
조각모음
- 이미 배치된 프로세스를 옆으로 옮겨 빈 공간들을 하나의 큰 덩어리로 만드는 작업
- 조각모음 순서
1. 조각 모음을 하기위해 이동할 프로세스의 동작을 멈춤
2. 프로세스를 적당한 위치로 이동(프로세스가 원래의 위치에서 이동하기 때문에 프로세스의 상대 주소값을 바꿈)
3. 작업을 다 마친 후 프로세스 다시 시작
고정 분할 방식의 프로세스 배치
- 분할된크기는 20KB이므로 40KB인 프로세스 A는 A1과 A2로 나뉘어 메모리에 할당
- 30KB인프로세스 C는 프로세스 C1과 C2로 나뉘는데, 메모리에 남은 공간이 없으므로 C2는 스왑영역으로 옮겨짐
고정 분할 방식과 내부 단편화
- 각 메모리 조각에 프로세스를 배치하고 공간이 남는 현상
- 고정 분할 방식은 내부 단편화를 줄이기 위해 신중하게 메모리의 크기를 결정해서 나눠야 하지만 사용하는 프로세스의 크기가 제각각이기 때문에 메모리를 얼마로 나누느냐에 관한 정답은 없음
가변 분할 방식과 고정 분할 방식의 비교
버디 시스템
버디 시스템의 작동 방식
1. 프로세스의 크기에 맞게 메모리를 1/2로 자르고 프로세스를 메모리에 배치
2. 나뉜 메모리의 각 구역에는 프로세스가 1개만 들어감
3. 프로세스가 종료되면 주변의 빈 조각과 합쳐서 하나의 큰 덩어리를 만듦
버디시스템의 특징
- 가변 분할 방식처럼 메모리가 프로세스 크기대로 나뉨
- 고정 분할 방식처럼 하나의 구역에 다른 프로세스가 들어갈 수 없고, 메모리의 한 구역 내부에 조각이 생겨 내부 단편화가 생김
- 비슷한 크기의 조각이 서로 모여 작은 조각을 통합하여 큰 조각을 만들기 쉬움
컴파일과 메모리 관리
변수와 메모리할당
컴파일러와 변수
- 컴파일러는 모든 변수에 대해 메모리를 확보하고 오류를 찾기위해 심벌 테이블 유지
- 컴파일러는 변수를 사용할 때마다 사용범위를 넘는지 점검
- 컴파일러는 모든 변수를 메모리 주소로 바꾸어 기계어로 된 실행 파일을 만듦
- 컴파일러에 의해 만들어진 변수의 주소는 상대주소임
'CS(Computer Science) > 운영체제' 카테고리의 다른 글
| 운영체제) #9 가상 메모리 관리 (0) | 2020.12.04 |
|---|---|
| 운영체제) #8 가상 메모리의 기초 (0) | 2020.12.04 |
| 운영체제) #6 교착상태 (0) | 2020.10.29 |
| 운영체제) #5 프로세스 동기화 (0) | 2020.10.29 |
| 운영체제) #4 CPU 스케줄링 (1) | 2020.09.24 |
- Total
- Today
- Yesterday
- 안드로이드
- password
- redis
- django server
- Hummingbird
- springboot
- DART
- Android
- chatting
- RecyclerView
- Django
- CHANNELS
- WAS
- 플러터
- Git
- Android Studio
- flutter
- flame
- mysql
- socket.io
- 에러
- 알고리즘
- Kotlin
- node.js
- 해결
- github
- Tutorial
- 코틀린
- 에러해결
- 안드로이드스튜디오
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |